We Need Type Information, Not Stable ABI
Published: Jan. 15, 2023, 5:42 p.m.
I've always been a strong proponent of dynamic linking, and last month a new Rust proposal dropped - interoperable_abi. It sparked discussions, plans forward, and my excitement was immeasurable. Then, one member said something that got me thinking. And after much thinking, I don't think ABI is what we need today. What we need is type information. Let me explain.
Preface
Rust has been a black hole of programming for many years - everything is being rewritten in it, and for a good reason - Rust is an incredibly powerful, fast, productive, yet safe language that is a joy to write in. One of the biggest shortcomings of the language is its bloat - compile times are rather slow, and binaries are relatively large. There's a reason for it - Rust prefers to compile everything from source, and code usually makes extensive use of its powerful type system.
Dynamic linking is a possible solution - unchanged libraries don't need to be recompiled, there is potentially stronger (compiled) code reuse across projects, and you gain the ability to load features incrementally. This sounds like a dream! So what's stopping us from doing it?
The Problem
One of the universally accepted truths, or an axiom if I may, is that for dynamic linking you need to stabilize the language ABI. And whenever such idea floats up, people are quick to point out, just how serious of a commitment it is, and how catastrophic it is to get it wrong. The consensus is that the default Rust repr, #[repr(Rust)], will not get stabilized any time soon, to not push Rust into a corner 10 years in the future.
interoperable_abi instead proposes a new repr, #[repr(interop)], that bases itself on the already stable C ABI, and extends it with features that make sense for Rust today. Some potential examples:
- Well defined fat pointers - slices, strings, trait objects.
- Optimizing enums to use less space.
- Support zero-sized fields in structs, without increasing the struct size.
The idea is great in principle, but all of this can be worked around and is not really the main problem blocking Rust from becoming a language that interops with other languages.
The Blind Spot
Manishearth, creator of diplomat, commented the following on the issue:
One thing that bothers me a bit is that I'm not actually sure if extern "interop" has taken a bite at the right chunk of the problem here, when looking from the POV of interop.
You have a tool like Diplomat or CXX that translates idiomatic Rust APIs to idiomatic FooLang APIs. It's going to find extern "interop" useful, but it's still going to have to generate some Rust wrappers around it. Not a huge change from the status quo. However, a lot of the things involved in making extern "interop" work will be very important.
In the cases most addressing the motivation (Diplomat, uniffi), work still needs to be done to translate to extern "interop", so I'm not sure if it actually buys much in those cases.
This is the comment that got me thinking. I've written a crate that makes traits shareable across dynamic libraries. Was #[repr(Rust)] the biggest problem in my efforts? No, it wasn't perfect, but I could walk around it by writing C structures for slices and alike. Are zero-sized fields key in the grand scheme of things? It wakes my OCD up, makes me very irritated, and I walked around it by writing my own custom bindings generator that ignores these fields, but in majority of cases, extra 1-8 bytes in a struct mean nothing. The main problem lies in bridging different languages together, and ensuring type safety across 2 libraries. That's the big fish.
The Root of All Solutions
Bridges between multiple languages and binaries, is a problem that has been in the works to be tackled by multiple parties. There are multiple approaches to this, but a compiler has the potential to do it better. So how would we solve the interoperability problem?
Prior art
Let's take a look at what different interoparability solutions do, and what their limitations are. Note that the list is not exhaustive and we will mostly focus on structures here.
cbindgen
cbindgen is an external tool that generates C/C++ headers by parsing your crate at source level. It's pretty amazing that it can do it, it can even parse dependency crates, but it suffers from a key limitation - it's buggy. Types often get misinterpreted, macros do not get automatically expanded, and so on. I don't have an example at hand, so the source is "trust me bro", but it's the actual reality of the tool.
diplomat
diplomat is a framework for allowing foreign languages to call into Rust. I've not used it, so I don't want to misrepresent it, but it has very extensive documentation. What it seems to boil down to is parsing a portion of Rust code, collecting types within, and then emitting a C layer, as well as other language implementations. They do define both ast and hir in diplomat_core. It seems to be something like a more reliable cbindgen with a limitation (or a feature, depending how you look) of not parsing your whole crate.
abi_stable
abi_stable is one of the oldest dynamic linking solutions - it provides runtime type checking when loading objects from multiple dynamic Rust libraries. It explicitly doesn't involve foreign languages, but I think it's still worth to mention, as it is the closest to what Rust people need today.
The core of it is the StableAbi trait. Let's take a look at it:
pub unsafe trait StableAbi: GetStaticEquivalent_ {
type IsNonZeroType: Boolean;
const LAYOUT: &'static TypeLayout;
const ABI_CONSTS: AbiConsts = _;
}
const LAYOUT is the meat of the crate - it contains type information accessible at runtime/compile-time. Then, there's a check_layout_compatibility function that takes 2 type layouts, and returns whether they are compatible. Mind you, it checks for compatibility, not equality. This implies assymetric relationship. For instance, if between library versions 0.1.0 and 0.1.1, struct Foo had an extra field appended to the end of it, &Foo from library 0.1.1 should be compatible for use by the old 0.1.0 version, because it simply doesn't care about the field. However, it would be invalid in the opposite case, because the real struct does not allocate or set the field expected by the new library, and that's what the function checks for.
safer-ffi
safer-ffi is a framework for building FFI in a safe manner. It's a really elegant design - unlike most FFI solutions, it doesn't attempt to perfectly parse and keep track of types. Instead, it works at type information level and derives special ReprC and CType traits that specify how to expand that type, using the information of the member types.
pub unsafe trait ReprC: Sized {
type CLayout: CType;
fn is_valid(it: &Self::CLayout) -> bool;
}
pub unsafe trait CType: Sized + Copy {
type OPAQUE_KIND: __;
fn c_short_name_fmt(fmt: &mut Formatter<'_>) -> Result;
fn c_var_fmt(fmt: &mut Formatter<'_>, var_name: &str) -> Result;
fn c_short_name() -> ImplDisplay<Self> { ... }
fn c_define_self(definer: &mut dyn Definer) -> Result<()> { ... }
fn c_var(var_name: &str) -> ImplDisplay<'_, Self> { ... }
}
It doesn't go as far as storing actual type information as a constant, but it uses Rust's type system to provide a well structured way to generate interoperable headers.
The Common Thread
All of the examples share one key feature - they leverage type information one way or the other. I think abi_stable and safer-ffi do it better, because using the type system itself makes a lot of sense - you are directly accessing the source of truth. Yet, they both suffer from one key limitation - implementing general information on types is a manual task requiring annotations for all user defined types, and manual implementations for the commonly used stdlib types. cbindgen attempts to remove the manual labor part, but suffers greatly from not being able to separate types clearly. Meanwhile, rustc clearly has all the necessary information at hand. If we were to expose it in some structured way, everyone could benefit.
Type Information is Enough
I built an example crate - ctti that provides just that - type information at compile-time. It's not complete - all primitives expose the information, user defined structures can implement it using provided macro, but unions, enums, and stdlib are out of luck. It's not ready for daily use, and it's not the point of it. The point of the crate is to show that type information is enough.
Mara Bos put the following image up on the GitHub issue:
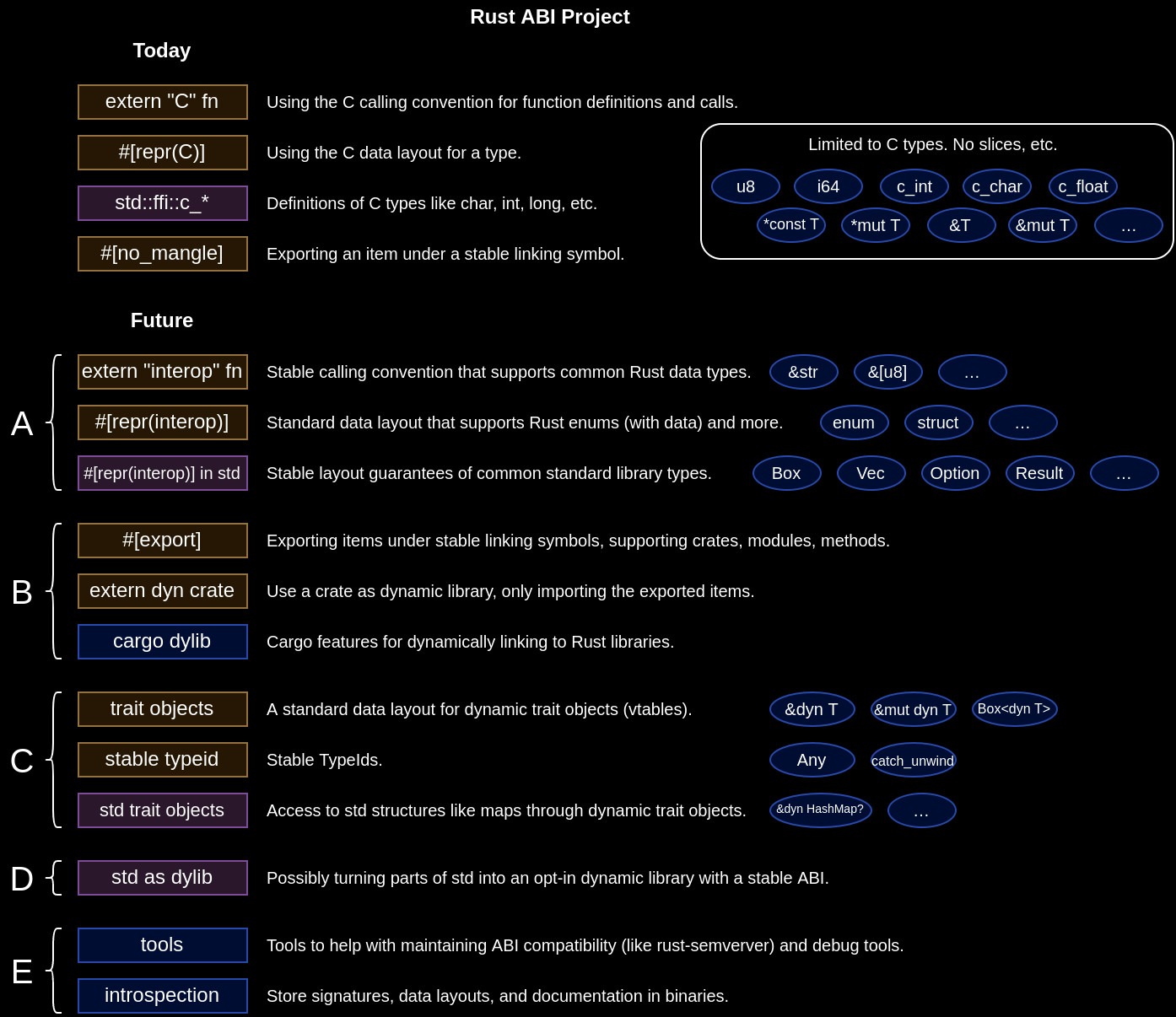
It's a potential plan of the Rust ABI project. Notice how features are built incrementally. Stage B suggests extern dyn crate, where a crate is loaded dynamically. Stage C aims to provide stable TypeIds. Stage E aims to store type layout in the binaries. I think it's a reasonable approach to not have scope creep, but how are B and C parts supposed to be implemented?
extern dyn crate
To load a crate dynamically, you'd need a mechanism in place to verify compatibility of the libraries. This is exactly what abi_stable does by utilising type layouts. Of course, extern dyn crate is a more elegant solution, but that seems like something that could be built easier after type layouts exist.
Stable TypeIds
There's an example type_id module in my crate that implements consistent type ID through a const fn. With type layouts, you don't need a special compiler-supported implementation of stable TypeIds - it can be outsourced to an external crate.
Change the Angle
My suggestion here is to change the angle interop is attacked from. If the endpoint is to store type information and documentation in binaries, as uncertain as things are, I think type information is the first thing needed to be built before other features are built, because it's the only foundation needed for the rest. Then Rust can do what it's always done - outsource experimentation of higher level features to external crates, and if there's demand - incorporate the winner to the standard library.
Conclusion
Is interoperable_abi a bad idea? Absolutely not - it would fix some C limitations imposed at a time when compile time computation based on types was unthinkable. It would be good, and it is needed at some point, but to truly make language interop possible, I think we need type information to build all the other necessary pieces of the interoperability ecosystem project.