Reinventing memflow-cli
Published: Jan. 28, 2022, 10:55 p.m.
Today I went for a casual walk around campus and for the next 2 hours started to think about memflow's CLI/daemon. We're essentially rewriting it for 0.2 with a much more flexible design. The question is how exactly the architecture is going to look like. Join me for some thoughts regarding that.
Overview
I am not going to talk much about the current design of the daemon - it's a hacked together mess with no sustainable road ahead. Instead, let's take a look at a reimagined architecture:
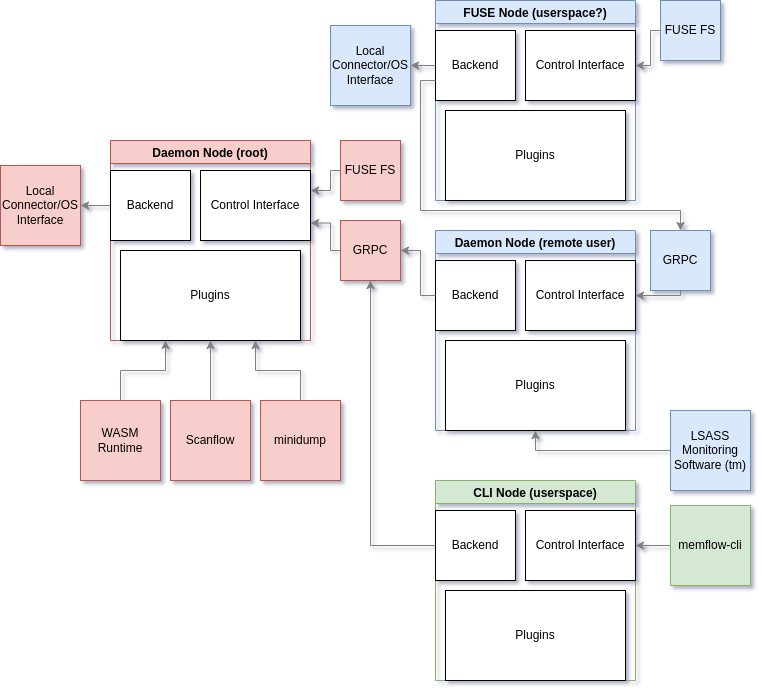
This basically allows us to meet a number of important criteria:
Common structured interface for CLI/FUSE/Web/etc.
Scalable remote access with composition (we could also call the nodes as parachains for the lols).
High performance FUSE interface with an option to run remotely.
Plugin system.
Allow user to load arbitrary plugins without compromising security of privileged daemon.
Basically this would serve as the ultimate "memflow framework" for applications and stuff alike.
Structure at its core
The diagram does not represent the relationships between various instances of connectors and OSs well enough, so let's take a look at some examples showing how it could look like.
1. Single daemon with FUSE
This is the simplest of cases - there is no interconnect and we basically have a single monolith executable handling everything. Inside the daemon we can create connectors and OSs. Say we have a Windows 7 coredump file with a QEMU windows 10 VM running. Performing nested instrospection we could have one (or both) of the 2 structures exposed by the daemon:
Candidate 1 - deeply nested structure
.
└── connector
└── coredump
└── win7-coredump
└── qemu_win10
└── win10-qemu
Candidate 2 - flattened structure
.
├── connector
│ ├── coredump
│ └── qemu_win10
└── os
├── win7-coredump
└── win10-qemu
I believe for simplicity (both from usability and manageability standpoints) option 2 makes way more sense. It may be harder to see connections this way, but we could also expose option 1 with a little bit of extra metadata and have best of both worlds.
This is pretty simple, but what if we want to build an OS on a remote connector?
2. Two nodes
The problem when you have multiple nodes is possibility of duplicate names of connectors/OSs. One way around it would be to essentially introduce backend names into the mix and prefix remote connectors/OSs with the backend name. For instance, say on the backend we have the following structure:
.
├── connector
│ ├── coredump
│ └── qemu_win10
└── os
└── windows
Where windows is an OS built on coredump connector.
Let's say we want to create a new windows instance on the remote daemon's qemu_win10 connector. To avoid name duplication issues, we would perform some clever renaming and have the following structure:
.
├── remote-daemon
│ ├── connector
│ │ ├── coredump
│ │ └── qemu_win10
│ └── os
│ └── windows
├── connector
│ ├── remote-daemon.coredump
│ └── remote-daemon.qemu_win10
└── os
├── remote-daemon.windows
└── windows
What's going on here? Why do we have duplication of connectors/OSs? Basically, we would love to allow user to work within the domain of a remote connection without involving local connection. Say you were to create a new OS on the local node, it would then exist only on it, but not the (parent) remote daemon. However, if we were to perform the operation on remote-daemon, it would then be available on both nodes, thus we would like to have an interface to deal with parent connections.
So ultimately, we can identify an OS in the following way:
backend1.backend2...backendN.os-name
NOTE: the following idea gets dropped later on due to atomicity reasons
# When performing any access operation, such as list or complete file read,
# we would need to traverse the structure. As you can imagine, it is very
# likely to be very slow to do with strings, thus let's introduce simple
# IDs for all connectors/OSs and backends. Thus, the core identification
# for an OS would look like this:
# backend1ID.backend2ID...backendNID.os-ID
# Where the original way would simply be an alias that gets translated
# locally on a high level operation (such as file open). In the end,
# tree traversal becomes incredibly simple - at every layer we just index
# into the ID and not have to perform any additional calculations. This
# starts to look awfully lot like an IP address or page table traversal,
# doesn't it?
Plugins
The idea for plugins is that they would define an optional filtering function for all the places where they should be accessible in (for instance, LSASS monitoring would only need to work on lsass.exe processes) and then define read/write/rpc implementations that directly work on a filtered process or memory view. This way there would be as little boilerplate needed as possible and everything would stay structured.
However, this is not the most abstract way to define a unit.
Directed Acyclic Graph
Boiling everything down, everything - all the directories to the backends, all the entries for OSs/connectors, all the processes within each OS and all the plugins that hook into different parts of the structure, is a node with edges to other nodes. Since it could be confusing to use the same term in 2 different contexts (framework nodes that get connect different daemons together), let's split this node up into 2 parts - a branch and a leaf. This way we can be sure we are in the clear that we are talking about internal structure of a single framework node.
branch - does not allow for specific RW ops, but instead links up to other (branch/leaf) nodes. Equivalent to a directory in FS terms.
leaf - does not direct itself to any other nodes, but instead provides actual functionality (RW or RPC). This is equivalent to a file in FS terms.
Whenever we traverse the structure to access anything from a physical memory file to a process minidump, we would end up using the following format:
branch1.branch2...branchN.leaf
NOTE: same as previously
# Where each branch has an ID it is being accessed with and an alias. Same
# with the leafs. For simplicity in storage/traversal branches and leafs
# would be separated on each of the branches, thus could have duplicate
# IDs between the 2 node types.
You could say this forms a tree, which could be the simpler way about it, but if we have 2 different paths to the same branch (say os/remote-daemon.win10 and remote-daemon/os/win10), then it actually becomes a graph, specifically an acyclic one or a DAG.
State Tracking
The DAG gets traversed whenever something needs to be accessed for the first time. However, once the leaf is opened we do not want it from changing unpredictibly. Thus upon access a reference counted handle would be given. More often than not, multiple repeated accesses would yield the same leaf, but if something were to change, let's say a different process takes place, or the minidump becomes outdated, then the given handle becomes dangling on its own and further accesses to the same path would yield a different handle.
Structurally each such handle could simply be another leaf that is in a somewhat flattened structure:
backend1ID.backend2ID...backendNID.handles.handle
handles could be given a hardcoded value of 0, thus we would have:
backend1ID.backend2ID...backendNID.0.handle
Another way about it would be a special handle traversal system. A handle may simply work as some sort of linked list - it would only contain the next backend and handle within. This way handles could be private information only shared with a single dependent node, path storage requirements become fixed and the traversal would look something like this:
local: handle -> backend1ID.handle1
backend1: handle1 -> backend2ID.handle2
...
backendN: handleN -> actual leaf
Opening the handle directly naturally yields itself. Although, there may need to be a way to disable multiple accesses to the same handle in some cases. Whenever the handle has no references to it it will be removed completely and resources freed.
There is an issue with reference counting across nodes, however. We must be able to handle cases whenever a node disconnects, the parent must know and subtract the right amount of from the count. This means the parent must keep track of how many references each downstream node has to each handle and this could end up rather messy.
DAG Syncing
Chances are entire DAG is not going to be synced - it would be too wasteful. DAG could be synced on-demand instead. Branch-by-branch. When we perform access from the user side we use actual names, not numerical IDs, because well, we don't know them! This needs to be worked out better, but I suppose we could either (open) access files by their names, or provide a name lookup. The problem with name lookup is that it's not really atomic, meaning sure, we get the IDs, but they could change inbetween calls! This is completely opposite from the handles - they will stay constant so long as they are open, thus we can easily use numeric IDs as we can rely on them staying constant.
I guess a good middle ground would be to access backends by IDs only when a handle is being accessed, because then we can guarantee a backend will not change so long as the handle itself is valid (and the handle becomes invalid when the dependent backend gets disconnected). For anything else, first accesses by string values make most sense - including backend paths. This way we will ensure atomicity of the actions and performance whenever leafs are open.
Accessing OS/process/connector traits directly
This could actually be implemented rather easily as an RPC leaf. The difference between RW and RPC is that with RW you perform a single push/pull operation while RPC sends data and waits for a response. This could work rather nicely in async context whenever all the operations need to be forwarded across nodes. It's only at the 2 ends when we will need to perform potentially blocking operations. Naturally, some form of threading will be needed to allow for concurrency. The interface end (like FUSE) can implement threading anyhow they want - say new thread per file access or something like that, but on the backend side (specifically local backend that contains actual connector/OS objects) will require some pooling mechanism to allow for quick and concurrent access to objects - some sort of auto cloning mechanism, or a multithreaded queue.
Summary
All in all, this could certainly be an architecture that works. I could be missing something very obvious, however. And of course, things do change as implementation comes around. But this should serve as a really good starting point.