Announcing mfio - Completion I/O for Everyone
Published: Dec. 7, 2023, 5 p.m.
I'm extremely proud to announce the first release of mfio, mfio-rt, and mfio-netfs! This is the most flexible Rust I/O framework, period. Let's get into it, but before that, warning: this is going to be a dense post, so if you want a higher level overview, check out the release video :)
mfio is an ambitious project that builds on the ideas of No compromises I/O. In the YouTube video, I say mfio is a framework defined by 2 traits, so, let's have a look at them:
#[cglue_trait]
pub trait PacketIo<Perms: PacketPerms, Param>: Sized {
fn send_io(&self, param: Param, view: BoundPacketView<Perms>);
}
pub trait IoBackend<Handle: Pollable = DefaultHandle> {
type Backend: Future<Output = ()> + Send + ?Sized;
fn polling_handle(&self) -> Option<PollingHandle>;
fn get_backend(&self) -> BackendHandle<Self::Backend>;
}
PacketIo allows the client to submit requests to I/O backends, while IoBackend allows the client to cooperatively drive the backend. Of course, there is way more to the story than meets the eye.
The aforementioned traits are the 2 nuclei of the framework, however, users will almost never want to use them - the traits are too low level! A higher level set of traits is provided to make the system not so alien to the user:
PacketIois abstracted through the likes ofPacketIoExt,IoRead,IoWrite,SyncIoRead,SyncIoWrite,AsyncRead,AsyncWrite,std::io::Read,std::io::Write.- Yes, there are synchronous APIs, but they only work when
T: PacketIo + IoBackend.
- Yes, there are synchronous APIs, but they only work when
IoBackendis abstracted throughIoBackendExt.
Completion I/O
Let's address the elephant in the room. This crate does not use readiness poll approach, instead, it centers itself around completion I/O. But first, what is completion I/O anyways?
Differences from readiness approach
Rust typically uses readiness based I/O. In this model, user polls the operating system "hey, I want to read N bytes right here, do you have them ready?" If OS has the data ready, it reads it and returns success, otherwise it returns a WouldBlock error. Then, the runtime registers that file as "waiting for readable" and only attempts to read again when OS signals "hey, this file is available for reading now".
In completion I/O, you hand your byte buffer to the I/O system, and it owns it until the I/O request is complete, or is cancelled. For instance, in io_uring, you submit an I/O request to a ring, which is then fulfilled by the operating system. Once you submit the buffer, you have to assume the buffer is borrowed until it's complete.
The primary difference between these 2 approaches is as follows:
In readiness based I/O, you can typically do 1 simultaneous I/O operation at a time. This is because readiness notifications just indicate whether a file contains data you previously requested, or not - it cannot differentiate which request it is ready for. This is actually great for streamed I/O, like TCP sockets.
In completion I/O, you pay a little extra upfront, but what you get is ability to submit multiple I/O operations at a time. Then, the backend (operating system), can process them in the most efficient order without having to wait for a new requests from the user.
In the end, completion I/O can achieve higher performance, because the operating system gets saturated more than in readiness based approach, however, it is typically more expensive at individual request level, which means it typically performs best in scenarios where a single file has multiple readers at different positions at the file, like databases, while not being eye shattering in sequential processing scenarios.
Our take
We built the system in a way that enables completely safe completion I/O, even when the I/O buffers are being borrowed. We do this through a relatively clunky synchronization system at the start and end of each I/O request - for borrowed data an intermediate buffer is created. However, if you feel wild, and do not want intermediate buffers, at the cost of safety, feel free to build your project with --cfg mfio_assume_linear_types, which will then assume futures will not get cancelled and give you a performance gain. However, the performance gains are only going to matter in situations where I/O is already incredibly fast, and by fast I mean ramdisk level fast. So don't bother with the switch if what you're doing is processing files - a better way to go about it is reusing heap allocated buffers, which will not allocate intermediates.
Integrated async runtime
mfio's IoBackend can be thought as a provider of asynchronous processing. Note that we are not aiming to replace tokio and alike, because we are only targeting the I/O aspect of the runtime, without touching scheduling. This means, there's no task spawning, or built-in time synchronization (by default) - we are only dealing with I/O. You can think of IoBackend as something slightly more powerful than pollster, but not by much - unlike pollster, we enable the backend to cooperate scheduling with the operating system, without the need for high-latency thread signaling, but nothing more.
Efficient completion polling
It's probably worth to go in a greater detail into this one. To make your I/O have low latency, you can't offload processing to a separate thread. But then, how do process I/O asynchronously, without blocking user's code, or wastefully polling the OS for completion without rest? We instruct the operating system to signal a handle (file descriptor on Unix) whenever I/O operations complete, and then we await for that handle. On Unix platforms, this corresponds to poll(2), while on Windows, it is WaitForSingleObject. The key enabler of this approach is the discovery that most I/O backends, like iocp, io_uring, epoll, or kqueue do not have to be polled for using the backend-specific functions, such as io_uring_wait_cqe(3). Speculation (would need to test): you may receive single-digit performance improvements from using the backend functions, however, as benchmarks show, using poll and WaitForSingleObject are sufficiently fast not to be deal-breakers.
Integration with other runtimes
If mfio does not have the feature set of tokio or async_std, then it is rather useless for real software. Plus, let's be real, nobody is going to switch to an unproven system just because it's fast. That's okay, because on Unix platforms we are able to seamlessly integrate with the biggest async runtimes! We do this by taking the exact same handle we normally poll for, and ask tokio (or async_std/smol) to do it instead. It's that simple! Then, instead of calling backend.block_on, we do the following:
Tokio::run_with_mut(&mut rt, |rt| async move {
// code goes here
}).await
Windows could in theory be supported in a similar manner, however, handles are currently not exposed to the same extent in async runtimes, therefore it's just not possible to do at the moment (although, this will soon change on async-io end!) In addition, there appears to be some complications with asynchronously waiting for objects, so it may also be a question whether waiting for said handle would even be possible, without changing mio/polling implementations to wait on handles, instead of IOCPs. There appears to be a solution using
NtCreateWaitCompletionPacket / NtAssociateWaitCompletionPacket and friends, however, these functions are not well documented, and only available since Windows Server 2012. Basically, the path is there, but it's not as pretty as on Unix.
Additional aspect worth mentioning is that the system is best used in thread-per-core scenarios, or, in Tokio's case, mfio-backend-per-task. It would work in other scenarios too, however, you would likely run into some inefficiencies. In addition, this recommendation is not yet firm - multithreading story is not solved, but should be worked out over the next year.
Colorless system
I make a claim that mfio does not have color, which means, it doesn't matter whether you use it from sync or async runtime. To be fair, depending on how you interpret the color problem, the claim may or may not be true.
What I mean by lack of color is that the system makes it trivial to create synchronous wrappers of the asynchronous functions. You can see that in the std::io trait implementations, and SyncIoRead/SyncIoWrite. So long as the object you wish to make synchronous wrappers for has both PacketIo and IoBackend, you should be trivially able to make it happen. This effectively makes it possible for the user to not care how the backend is implemented. Meanwhile, the backend is always async.
Cutting edge backends for OS interfacing
mfio-rt attempts to define a standard async runtime, which can then be implemented in various ways. The native feature enables built-in backends that interface directly with the OS through various APIs, such as:
- io_uring
- iocp
- epoll/kqueue (leveraging
mio) - Threaded standard library fallback
iocp and io_uring backends enable for far greater random access performance than the likes of std or tokio.
mfio-rt is still at its infancy - we currently have Fs and Tcp traits defined that allow the user to perform standard OS related operations, however, the usage differs wildly from typical async runtimes. Ideally, what I'd want to expose is a global feature flag that allows the user to install a global runtime, that can then be used from regular function calls, like so:
use mfio_rt::fs;
use mfio::prelude::v1::*;
#[tokio::main]
#[mfio_rt::init(integration = 'Tokio')]
async fn main() {
// We don't need mutable file with mfio
let file = fs::File::open("test.txt").await.unwrap();
let mut buf = vec![];
file.read_to_end(0, &mut buf).await.unwrap();
println!("{}", buf.len());
}
Additional thing worth adding is Time trait so that more applications could be built in a runtime-agnostic way, however, that is not the highest priority, since you can already do sleeps with tokio or smol, and also, how many "small" features away are we from being a fully fledged runtime, capable of completely displacing tokio?
Network filesystem
As a bonus, we have an experimental network filesystem implementation, going by the name of mfio-netfs. It was built purely as a test, and is to be considered as a toy, because:
- I have personally encountered hard to reproduce hangs.
- There is absolutely zero encryption, checksumming, or request validation.
- The communication protocol is built on interpreting C struct as bytes, and going the other way around
- It was not a fun 5 hours spent in
rr, trying to figure out why my code would segfault with a nonsensical call stack. However, it was also a good experience, because it let me track down a bug inio_uringbackend implementation. This crash is the type of scary stuff you shouldn't expect from Rust codebase, and yetmfio-netfshas the potential!
- It was not a fun 5 hours spent in
As a result, upon running it, you will see a big warning advising against using it in production, and please listen to it! I have plans to write a proper network filesystem, built on quic/h3, which should potentially achieve much better performance than it is getting now, because the nature of mfio favors almost-non-sequential message passing that is unlike TCP (which we currently use). However, it is a good sub-2000 LoC example to dig into and see how one would implement an efficient I/O proxy.
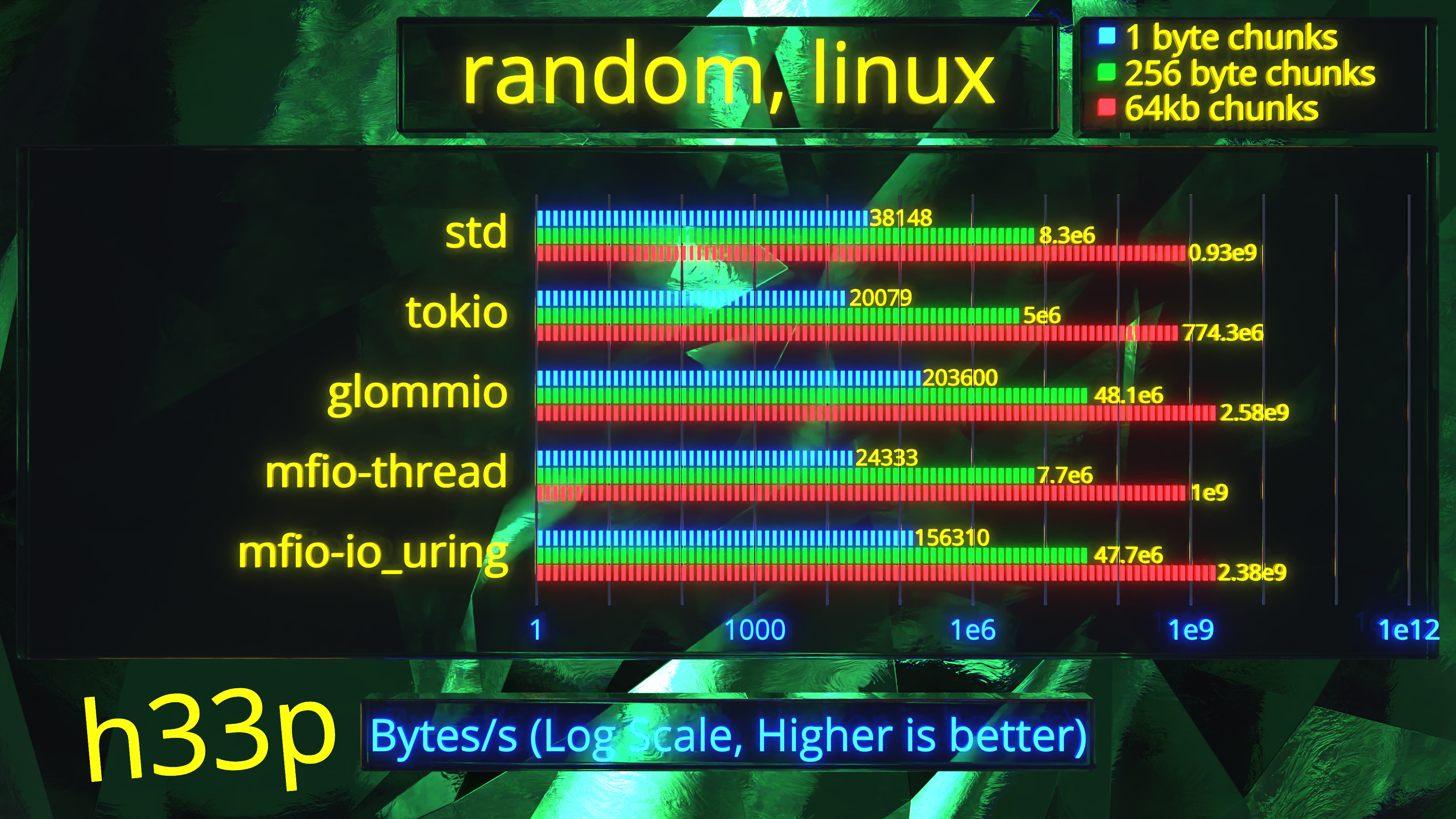
Exhaustive benchmarks
I say mfio is fast, but how fast? If you wish to see an overview of the results, please see the release video. However, if you wish to look at raw data, check out the reports:
Testing methodology
The exact setup is available in mfio-bench repo.
The reports are not the clearest, because I originally planned to only use them in the video, but figured not all data will fit there. Here are some important points:
- All graphs are log scale. This allows one to compare 2 backends percentage wise.
- You will find 1ms latency attached to all local results. This is false, there is no latency - files are local.
- However, all benchmarks also include
mfio-netfsresults, which go to a remote node. Read size mode results too have no added latency - the remote node is a VM running locally.
- However, all benchmarks also include
- Latency mode results are going to a local VM running SMB server, and artificial latency is setup.
- However,
mfio-netfsbypasses SMB - it goes to amfio-netfsserver running on the same SMB node - identical latency as SMB.
- However,
- In latency mode, X axis is the latency (ms), not bytes/s.
- For completion I/O, we set up multiple concurrent I/O requests - up to 64MB of data being in flight, to be precise.
- For
glommio, we did not useDmaFile, because our reads are unaligned. It is possibleglommiocould achieve better performance if it were not using buffered I/O. Same withmfio, we could achieve better performance, if we used unbuffered I/O, however, that makes us unable to easily perform unaligned reads, so for now, we are sticking with buffered.
Results
From the results we can see that mfio backends, especially io_uring and iocp achieve astonishing performance in random tests. In addition, in latency comparison, mfio-netfs achieves better results than going through SMB on Linux, while on Windows, we have similar results.
Sequential performance is not the best - OSs can perform read-ahead rather well, making std perform much better than any completion I/O system. That is the tradeoff - with completion I/O, you have much more complex software architecture, that incurs bigger constant overhead, however, once you start using it its fullest, then that architecture starts to pay off big time.
Learnings from No compromises I/O
For mfio core, I attempted to use the model detailed in the No compromises I/O post, however, I soon realized that attaching a backend to every I/O request future is undesirable and too complicated to handle. Instead, I opted for a different approach where each top level future is combined with the I/O backend, and both are then processed sequentially. This model makes it not possible to efficiently share the I/O backend across threads, however, the method's simplicity outweighs the potential benefits.
In addition, I made the base I/O objects be simple and do away with the streams and callbacks. The reason for that is there's more performance to be gained from implementing the most commonly used packets as standard to the system. The flexibility mentioned in the post is still there, however, it is now opt-in rather than forcing you to take performance loss.
It is natural to have the design change over the months, and I'm glad to have messed around with the original design, because I learnt quite a bit about making better software architecture decisions.
Closing words
This is a big release, and it has been long coming. I do have a few important shaping changes to do, but the overall spirit of the library should stay the same. In addition, I have quite a few project ideas building on top of mfio, and of course, migrating memflow to async. Should you want to try the system out, head to the mfio repo, and do set it up! If you have any questions or feedback, feel free to get in touch, it is greatly appreciated.